Neural Radiance Fields (NeRFs)
This project focuses on implementing a Neural Radiance Field (NeRF) to reconstruct 3D scenes from 2D images. Utilizing deep learning, we aim to train a model that predicts color and density at any point in space, enabling the rendering of detailed and realistic scenes.
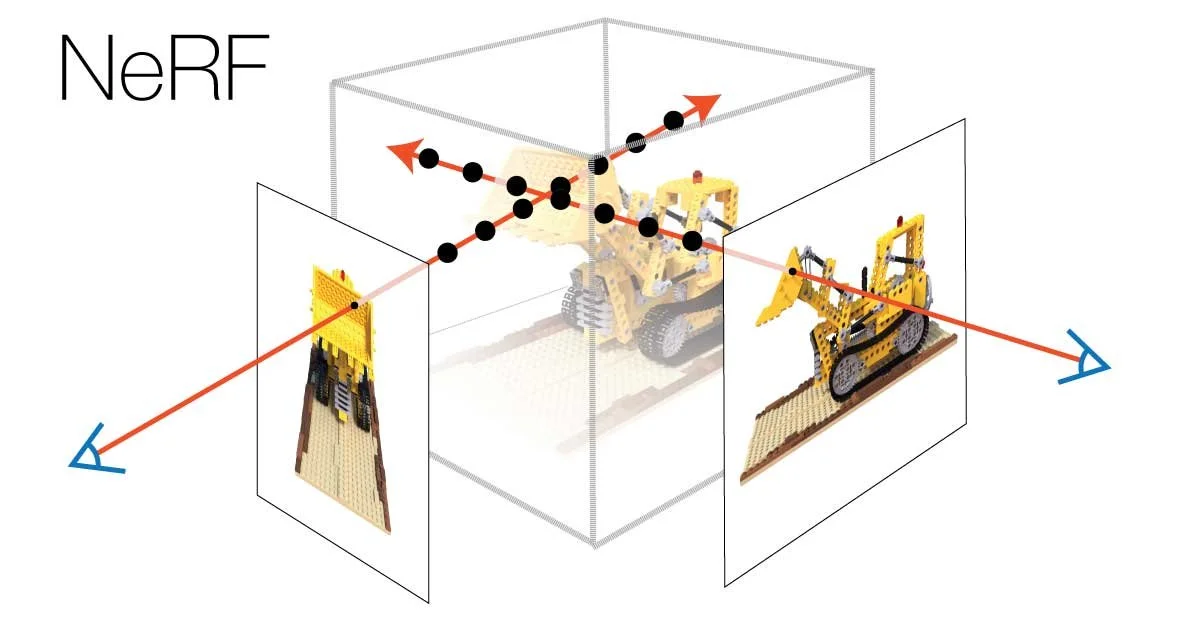
Figure from “NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis”
Overview
The core idea behind NeRF is to minimize the differences in how an object appears when photographed from various angles. This is crucial for creating consistent and realistic 3D representations.
To accomplish this, NeRF takes into account the camera's location, focusing on its distance and direction relative to the object, as well as the camera's tilt and angle at the moment the photo is captured.
In processing images, NeRF zeroes in on two key aspects: the density and color of points along the camera's view to the object. It evaluates how likely it is for the camera's view to end at each point in space, and what color these points should be. This dual focus allows for the creation of detailed and accurate color representations of the object.
By synthesizing this data from images taken from various angles and positions, NeRF is able to construct highly detailed and lifelike 3D models.
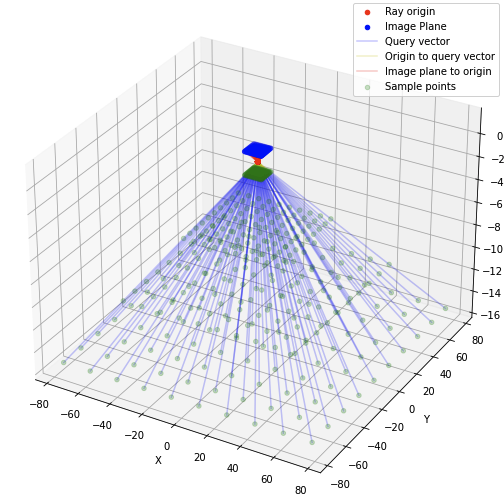
Ray Casting
In traditional graphics, the scene is transferred onto the image plane using perspective projection, which replicates how our eyes perceive depth and distance. The NeRF algorithm utilizes ray-casting. This approach projects the scene onto the image plane by tracing 'rays' from the camera to various points in the scene, thereby creating a map of how the scene looks from the camera's perspective.
The image on the left visually demonstrates the ray-casting method employed to create query points for the model. These query points, shown in green, are produced by sampling along the path of the ray-casting method, depicted in blue, at various intervals.
Volume Rendering
The model generates a color and volume density for each depth point along the ray. These values are used to calculate the color of each pixel in the image. The process involves iterating through each depth value in the image, computing the accumulated transmittance (T) and opacity (alpha) at each point. These are then multiplied by the output color for the current depth position. Summing up these values across all depth points yields the predicted color for each pixel.

Dataset and Model
The model architecture was designed based on the structure outlined in the original paper "A Brief Introduction to Neural Radiance Fields." However, due to computational constraints, it was scaled down to four multi-layer perceptrons (MLPs), each with 256 hidden units and ReLU activation functions.
Training was conducted using the official “chair” dataset employed by the original NeRF paper. The image on the right displays a selection of images from this dataset.
Results
The video on the left presents the outcomes of the adapted NeRF model. This video showcases the model's capabilities in creating detailed and lifelike 3D images, illustrating textures and realistic lighting effects that the model can achieve, even with its scaled-down architecture.